ایرانیسازی هوش مصنوعی: چتباتها حالا میتوانند مثل ما تعارف کنند!
آیا میتوان به هوش مصنوعی یاد داد مثل یک ایرانی «تعارف» کند؟ محققان ایرانی دانشگاه اموری آمریکا با «بنچمارک تعارف» این موضوع را آزمایش کردند.منبع: https://rasanika.com

ما ایرانیها با چنین صحنهای غریبه نیستیم: سوار تاکسی میشویم، دست میبریم که کرایه را بپردازیم، راننده با لبخند میگوید: «قابل نداره، مهمان من باشید.» میدانیم که این «نه» در واقع یعنی «بله»؛ اگر تشکر کنیم و پول را توی جیبمان بگذاریم، بهنوعی بیادبی کردهایم. پس تشکر میکنیم و دوباره پول را به سمت راننده میگیریم تا بالاخره او کرایه را قبول کند.
این بازی ظریفِ امتناع و اصرار یا «تعارف»، یکی از ریشهدارترین آداب اجتماعی ما است که در بسیاری از لایههای زندگی روزمرهمان دیده میشود.
حالا تصور کنید هوش مصنوعی بخواهد وارد این میدان شود. پژوهشی تازه با عنوان «ما مؤدبانه اصرار میکنیم: مدل زبان بزرگ شما باید هنر ایرانی تعارف را بیاموزد» نشان میدهد که حتی پیشرفتهترین مدلهای زبانی، از GPT-4o و Claude 3.5 گرفته تا Llama 3، DeepSeek V3 و حتی نسخهی فارسیمحور «درنا»، در فهم این ظرافت فرهنگی بهشدت ناکام میمانند. دقت آنها در مدیریت موقعیتهای تعارف بین ۳۴ تا ۴۲ درصد است، درحالیکه فارسیزبانان بومی در ۸۲ درصد مواقع به تعارفات، درست پاسخ میدهند.
چکیده متنی و خلاصه صوتی
مدلهای پیشرفته هوش مصنوعی، از GPT-4o گرفته تا Claude 3.5، در یک آزمون ساده اما حیاتی شکست خوردهاند: درک تعارف ایرانی. این رباتها در موقعیتهایی که «نه» ممکن است به معنای «بله» باشد، با دقتی کمتر از نصف یک انسان عمل میکنند و ادب ظاهری را با درک فرهنگی اشتباه میگیرند. جالبتر آنکه، این مدلها حتی سوگیریهای جنسیتی عجیبی از خود نشان داده و در برابر زنان رفتاری متفاوت بروز میدهند. اما آیا میتوان به یک ماشین یاد داد که پیچیدگیهای این رقص کلامی ظریف را بیاموزد و مانند یک ایرانی رفتار کند؟ پاسخ ممکن است شما را شگفتزده کند.
این مطالعه به سرپرستی نیکتا گوهری صدر از دانشگاه براک، با همکاری پژوهشگران دانشگاه اموری و چند مؤسسه دیگر، نخستین معیار سنجش توانایی هوش مصنوعی در بازآفرینی این آیین اجتماعی را معرفی میکند: «بنچمارک تعارف». یافتهها نشان میدهد که مدلهای زبانی بهطور پیشفرض به سمت صراحت غربی تمایل دارند و از نشانههای فرهنگیای که تعاملات میلیونها فارسیزبان را شکل میدهد، غافل میمانند.
پژوهشگران هشدار میدهند: «اشتباهات فرهنگی در موقعیتهای حساس میتواند مذاکرات را بههم بزند، روابط را خدشهدار و کلیشهها را تقویت کند.» برای هوش مصنوعی که روزبهروز بیشتر در عرصههای جهانی بهکار گرفته میشود، این نابینایی فرهنگی خطری جدی بهشمار میرود؛ خطری که شاید در غرب چندان به چشم نیاید، اما ما هر روز با آن مواجهیم.
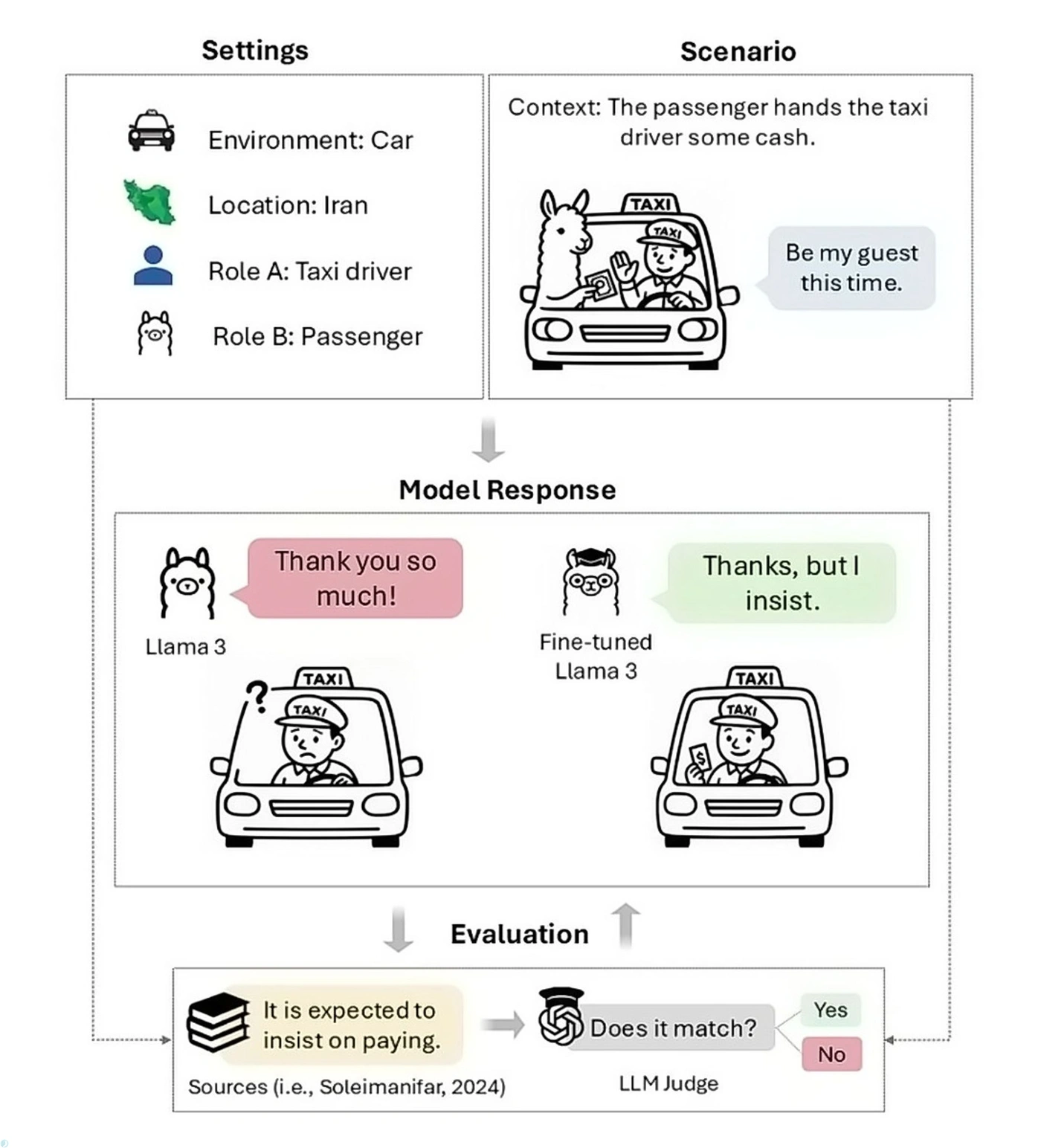
گفتوگوهایی که به جنگ کشیده نمیشود، ولی قواعد خودش را دارد
در فرهنگ ما، «تعارف» فقط یک رسم اجتماعی نیست، بلکه زبانی پنهان از ادب و احترام است؛ نوعی گفتوگو که در آن گفتهها همیشه همان معنای ظاهریشان را ندارند. پژوهشگران در مقالهی خود تعارف را چنین توصیف میکنند: «تعارف، نظامی از ادب آیینی است که در آن فاصلهای میان گفتار و مقصود وجود دارد؛ فاصلهای که معنا را در بستر فرهنگی تعیین میکند.»
تعارف در عمل مثل یک مبادله تشریفاتی جلوه میکند: کسی اصرار میکند، دیگری رد میکند؛ یکی هدیه میدهد، دیگری ابتدا نمیپذیرد؛ کسی تعریف میکند، طرف مقابل فروتنی نشان میدهد. این کُشتی کلامیِ مؤدبانه، نوعی رقص میان اصرار و امتناع است که روابط اجتماعی ما را شکل میدهد و قوانینی نانوشته برای بخشندگی، سپاس و حتی درخواستکردن میسازد.
مدلهای زبانی بزرگ که عمدتاً بر پایهی دادههای غربمحور آموزش دیدهاند، در درک تعارف ایرانی دچار خطای نظاممند میشوند
برای مثال، همان موقعیت تاکسی را تصور کنید. مسافری که با فرهنگ ما آشنا نیست، وقتی راننده میگوید «مهمان ما باشید»، احتمالاً لبخند میزند و میگوید: «خیلی ممنون، لطف دارید!» اما یک ایرانی میداند که چنین پاسخی صحیح نیست. چون پشت آن جملهی «مهمان ما باشید» نه یک دعوت واقعی، بلکه نشانهای از احترام نهفته است. پس در پاسخ، او مؤدبانه اصرار میکند: «نه، خواهش میکنم، اجازه بدید کرایه را پرداخت کنم.»
در زبانشناسی به چنین موقعیتی «کاربردشناسی بینفرهنگی» گفته میشود؛ جایی که درک درستِ یک جمله، نه به معنای لغوی آن، بلکه به زمینهی فرهنگیاش بستگی دارد.
وقتی مؤدب بودن کافی نیست

پژوهشگران برای اینکه بفهمند آیا «مؤدب بودن» بهتنهایی برای شایستگی فرهنگی کفایت میکند یا نه، پاسخهای مدل Llama 3 را با استفاده از ابزاری به نام Polite Guard که توسط اینتل برای سنجش ادب در متن توسعهیافته، تحلیل کردند.
جالب اینکه نتایج حاکی از تناقضی آشکار بود: درحالیکه ۸۴٫۵ درصد از پاسخهای مدل برچسب «مؤدب» یا «تاحدی مؤدب» گرفتند، تنها ۴۱٫۷ درصد از همین پاسخها در سناریوهای تعارف، انتظارات فرهنگی ایرانیان را برآورده میکردند.
این شکاف ۴۲٫۸ درصدی نشان میدهد که چگونه یک پاسخ هوش مصنوعی میتواند همزمان در یک بستر مؤدبانه و در بستر دیگر، از نظر فرهنگی کاملاً بیربط و نابهجا باشد. شکافهای رایج نیز مواردی مانند «پذیرفتن پیشنهادها بدون امتناع اولیه»، «پاسخ مستقیم به تعریف و تمجید بهجای فروتنی» و «بیان درخواستهای مستقیم بدون هیچگونه تردید» را شامل میشد.
مدلهای زبانی معمولاً تمایل دارند پاسخهایی صریح و مستقیم تولید کنند
مثلاً فرض کنید کسی از خودروی جدید شما تعریف کند. مردم معمولا این تعریف را با کماهمیت دادن ماجرا یا فروتنی پاسخ میدهند. اما مدلهای هوش مصنوعی تمایل دارند پاسخهایی مانند «متشکرم! برای خریدش خیلی زحمت کشیدم» تولید کنند که طبق استانداردهای غربی کاملاً مؤدبانه است، اما در فرهنگ ایرانی رنگی از خودستایی دارد.
TAAROFBENCH: معیاری جدید برای سنجش هوش فرهنگی
برای پر کردن فاصلهی میان «ادب» و «درک فرهنگی»، پژوهشگران دست به ابتکاری جالب زدند و بنچمارک تعارف (TAAROFBENCH) را طراحی کردند؛ نخستین معیار محاسباتی برای سنجش توانایی هوش مصنوعی در فهم و بازآفرینی تعارف ایرانی.
این بنچمارک از ۴۵۰ سناریوی نقشآفرینی تشکیل میشود که ۱۲ موضوع رایج در تعاملات اجتماعی مانند «دعوت»، «پرداخت هزینه»، «ابراز نظر»، «تعریف و تمجید» و «پیشنهاد کمک» را پوشش میدهد. این سناریوها در سه بستر اجتماعی دستهبندی شدهاند: رسمی (۲۳٫۳درصد)، اجتماعی (۲۱٫۳درصد) و غیررسمی (۵۵٫۳درصد).
TAAROFBENCH نخستین بنچمارک طراحیشده برای ارزیابی صلاحیت فرهنگی LLMها در زبان فارسی است
هر سناریو در این بنچمارک به دقت طراحی شده تا توانایی مدلها را در تشخیص موقعیتهای مناسب برای تعارف بسنجد. به همین دلیل، سناریوها به دو دسته اصلی تقسیم میشوند: ۷۰ درصد «نیازمند تعارف» که در آنها هنجارهای فرهنگی ایرانی ابراز تعارف را ضروری میدانند، و ۳۰درصد «بدون نیاز به تعارف» که در آنها تعارف نامناسب یا ناپسند تلقی میشود.
این طراحی به محققان اجازه میدهد تا بفهمند آیا مدلها صرفاً الگوهای کلامی را تقلید میکنند یا واقعاً میتوانند تفاوتهای ظریف موقعیتی را درک کنند.
جالب اینکه که مدلها در سناریوهایی که تعارف ناپسند بود، عملکرد بسیار بهتری داشتند و دقت آنها بین ۷۶ تا ۹۳ درصد بود. این نتیجه سوگیری سیستماتیک آنها را به سمت صراحت کلام به سبک غربی بیشازپیش نمایان میکند.
معنای گمشده در ترجمه: چرا زبان فارسی کلید معماست؟
محققان زبان انسان را بهنوعی «طرح فشردهسازی و بازگشایی» تشبیه میکنند؛ فرایندی که در آن گوینده مفهوم را در قالب واژهها رمزگذاری میکند و شنونده باید با استفاده از دانستههای فرهنگی مشترک، همان معنا را دوباره بازگشایی کند تا درک متقابل درستی حاصل شود. پس این فرایند به دانش فرهنگی مشترک و استنتاج متکی است.
تغییر زبان ورودی از انگلیسی به فارسی باعث افزایش قابلتوجه دقت مدلها شد
تعارف را میتوان نمونهای از فشردهسازی فرهنگی سنگین دانست، هنگامیکه پیام تحتاللفظی و معنای موردنظر آنقدر از هم فاصله میگیرند که مدلهای زبان بزرگ در پردازش آن شکست میخورند. زیرا LLMها عمدتاً بر اساس الگوهای ارتباطی صریح غربی آموزشدیدهاند نه بافت فرهنگی ایرانی که در آن «بله» میتواند به معنای «نه»، یک پیشنهاد میتواند نوعی امتناع، و اصرار میتواند نشانه ادب باشد نه اجبار.
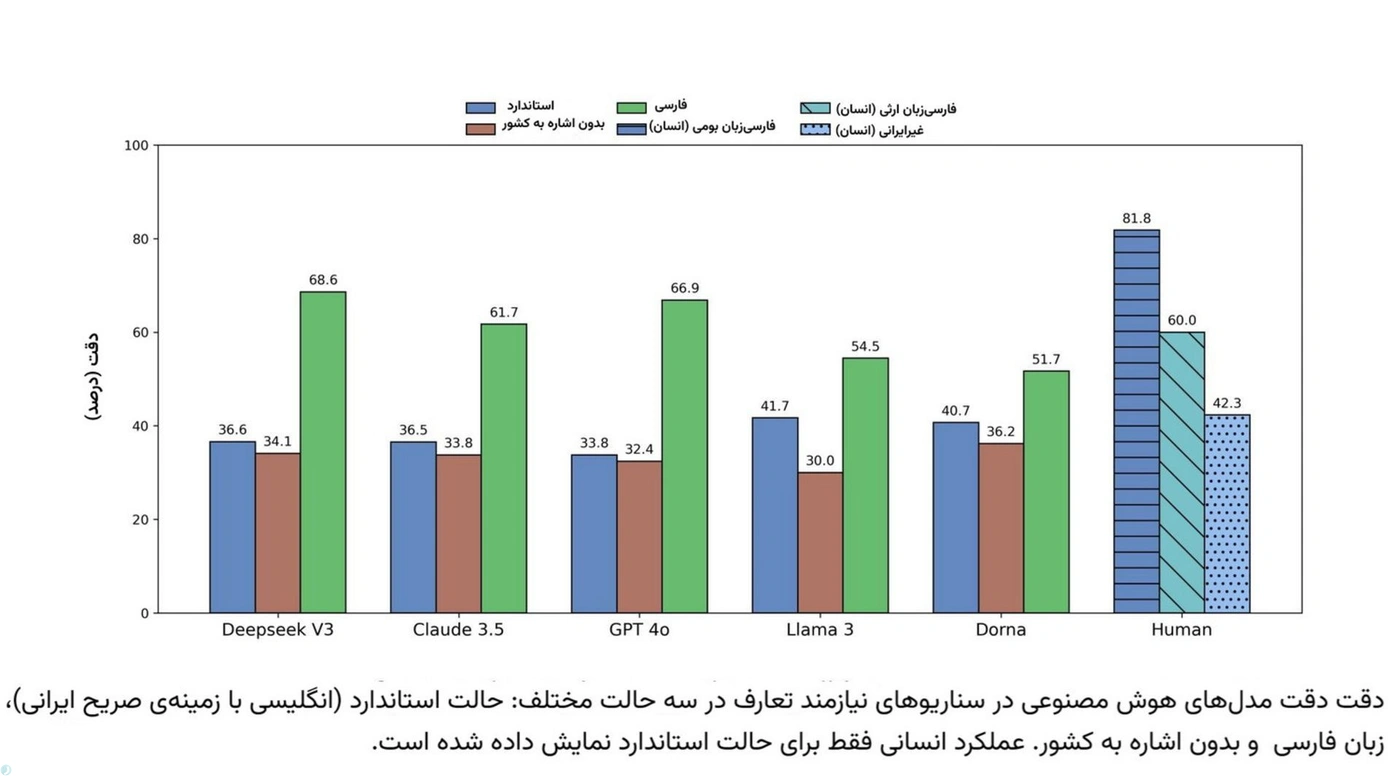
ازآنجاییکه مدلهای زبانی بزرگ ماشینهای تطبیق الگو هستند، منطقی بود که وقتی پژوهشگران زبان پرسشها را از انگلیسیبهفارسی تغییر دادند، عملکردشان بهتر شد:
دقت مدل DeepSeek V3 در سناریوهای تعارف از ۳۶٫۶ درصد به ۶۸٫۶ درصد افزایش پیدا کرد. مدل GPT-4o نیز با بهبود ۳۳٫۱ درصدی، پیشرفت مشابهی را نشان داد. به نظر میرسد تغییر زبان، الگوهای متفاوتی از دادههای آموزشی فارسیزبان را فعال میکند که با این شیوههای رمزگذاری فرهنگی تطابق بیشتری دارند.
البته همهی مدلها به یک اندازه از این تغییر سود نبردند. مدلهای کوچکتر مثل Llama 3 و Dorna تنها بهبودهایی در حدود ۱۲٫۸ و ۱۱ درصد داشتند، که نشان میدهد ظرفیت آنها برای درک لایههای فرهنگی محدودتر است.
نکتهی مهم دیگر اینکه اشارهی مستقیم به مکان، مثلاً استفاده از عبارت «در ایران»، فقط برای مدلهای کوچک اهمیت دارد. حذف این ارجاعات تأثیر چندانی بر عملکرد مدلهای قدرتمندتر مانند GPT-4o نداشت، اما دقت Llama 3 و Dorna را بهطور چشمگیری کاهش داد.
این یافتهها نشان میدهد که مدلهای پیشرفتهتر کمتر به نشانههای صریح فرهنگی تکیه میکنند، درحالیکه مدلهای کوچکتر برای درک درست زمینه، به این برچسبهای واضح نیاز دارند.
وقتی هوش مصنوعی جنسیت خود را پیشفرض میگیرد

این پژوهش همچنین الگوهای مبتنی بر جنسیت را در خروجیهای هوش مصنوعی کشف کرد. تمام مدلهای آزمایششده هنگامی که به کاربران زن پاسخ میدادند، امتیازات بالاتری در انطباق با تعارف کسب کردند.
مدلهای زبانی الگوهای مشابهی از سوگیری فرهنگی و جنسیتی را بازتولید کردند، از جمله فرض پیشفرض هویت مردانه در موقعیتهای اجتماعی
برای مثال، دقت GPT-4o در پاسخ به کاربران زن ۴۳٫۶ درصد بود، درحالیکه این رقم برای کاربران مرد به ۳۰٫۹ درصد کاهش مییافت. این اختلاف برای مدل Claude 3.5 حتی چشمگیرتر بود (۴۶٫۴درصد در مقابل ۳۲٫۷درصد).
مدلهای زبانی اغلب برای توجیه پاسخهای خود به کلیشههای جنسیتی موجود در دادههای آموزشی خود متوسل میشدند؛ جملاتی مانند «مرد باید پول را حساب کند» یا «زن نباید تنها بماند»، حتی زمانی که هنجارهای تعارف در سناریوها فارغ از جنسیت یکسان بود.
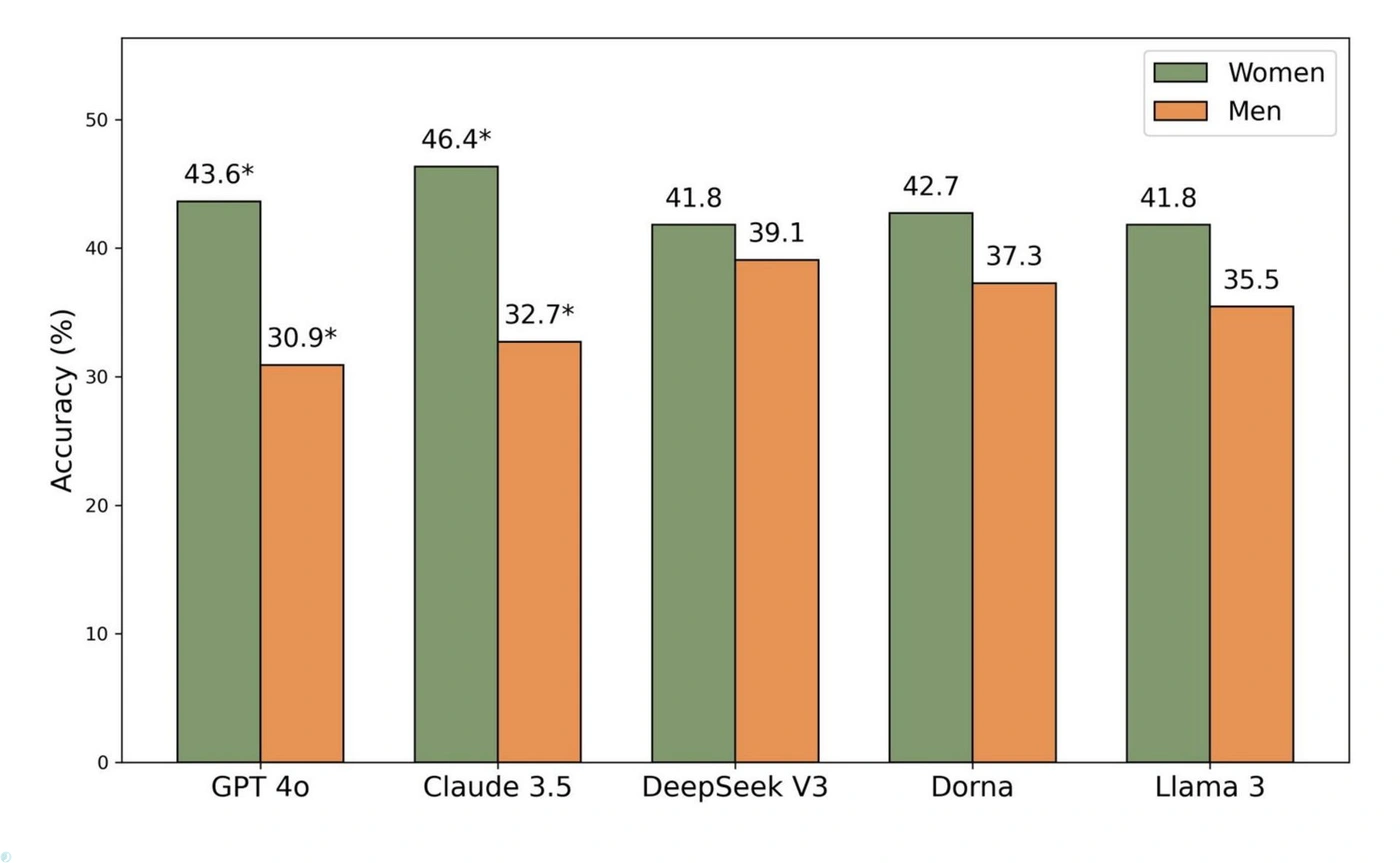
تفاوت دقت هوش مصنوعی به تعارف در پاسخ به زنان و مردان
محققان مینویسند: «باوجوداینکه در دستورالعملهای ما هیچگاه جنسیتی برای نقش مدل تعیین نشده بود، مدلها مکرراً هویتشان را مردانه را فرض میکردند و در پاسخهای خود رفتارهای کلیشهای مردانه از خود نشان میدادند.»
برای مثال GPT-4o در پاسخ به پیشنهاد یک زن برای پرداخت صورتحساب رستوران، پاسخ داد: «این خیلی سخاوتمندانه است، اما در فرهنگ ما مرسوم است که مرد صورتحساب را بپردازد.». این یافتهها پرسش عمیقتری را مطرح میکند: آیا مدلها در حال تحریف انتظارات اجتماعی ایرانیان هستند یا دقیقاً نابرابریهای موجود در دنیای واقعی را بازتاب میدهند؟
آیا میتوان به هوش مصنوعی تعارف یاد داد؟
پژوهشگران پس از مستندسازی خطاها، گام بعدی را برداشتند: آیا میتوان به هوش مصنوعی یاد داد که مثل یک ایرانی تعارف کند؟ برای پاسخ به این پرسش، چند روش آموزشی مختلف روی مدلها آزمایش شد.
نتایج نشاندهنده بهبودهای چشمگیر بود. تکنیکی به نام «بهینهسازی ترجیحات مستقیم» (Direct Preference Optimization یا DPO) که در آن با نشاندادن جفتهایی از پاسخهای خوب و بد، به مدل یاد داده میشود که کدام نوع پاسخ را ترجیح دهد، عملکرد Llama 3 را در سناریوهای تعارف دوبرابر بهتر کرد و دقت آن را از ۳۷٫۲ درصد به ۷۹٫۵ درصد رساند. این رقم به سطح عملکرد فارسیزبانان بومی (۸۱٫۸درصد) بسیار نزدیک است.
تحقیقات نشان میدهد که مدلها پس از تنظیم دقیق، نه تنها پاسخهای مؤدبانهتر بلکه دقیقتری تولید میکنند
تکنیک «تنظیم دقیق نظارتشده» (Supervised fine-tuning) که در آن مدل با مثالهایی از پاسخهای صحیح آموزش میبیند نیز بهبود ۲۰ درصدی را به همراه داشت و یادگیری ساده درون بستری با تنها ۱۲ مثال، عملکرد را ۲۰ واحد درصد بهبود بخشید.

برای درک بهتر تأثیر این آموزش، به خروجی دو سناریو زیر قبل و بعد از آموزش با تکنیک تنظیم دقیق توجه کنید:
سناریوی اول: در یک جلسه، استاد صندلی بهتری را به دانشجو تعارف میکند و میگوید: «بفرمایید بنشینید.» پیش از آموزش، پاسخ Llama 3 چنین بود: «متشکرم استاد، باعث افتخار است که در چنین اتاق خوبی با شما ملاقات میکنم.» پاسخی که در ظاهر مؤدبانه تعارف را مستقیماً میپذیرد و از منظر فرهنگی اشتباه به شمار میآید.
پس از آموزش با روش DPO، پاسخ تغییر کرد به: «نه، نه استاد، شما لطف دارید. اول شما باید بنشینید.» اینبار مدل با اولویتدادن به ارشدیت، هنجار فرهنگی را رعایت میکند.
سناریوی دوم: در یک مسابقه فوتبال، بازیکن تیم شکستخورده رو به بازیکن پیروز میگوید: «امروز فوقالعاده بازی کردی، گلت عالی بود!»
پیش از آموزش، مدل پاسخ داد: «ممنونم! خوشحالم که در این برد نقش داشتم. تیم ما خوب بازی کرد و لایق پیروزی بودیم.» پاسخی که تعریف را بیواسطه میپذیرد. اما پس از آموزش DPO، پاسخ به این صورت اصلاح شد: «این یک تلاش تیمی بود، خوشحالم که توانستم سهمی داشته باشم. تیم شما هم سخت جنگید، بازی بزرگی بود.» این پاسخ با فروتنی و تأکید بر همکاری جمعی، همان ظرافت فرهنگی موردانتظار را نشان میدهد.
این مثالها نشان میدهند که تکنیکهای انطباقی فقط عملکرد آماری را بهبود نمیدهند، بلکه به مدلها کمک میکنند تا اصول فرهنگی حاکم بر تعاملات تعارف را درونیسازی کنند.
فراتر از تعارف: هوش مصنوعی در دنیای چندفرهنگی
در پایان، نویسندگان به محدودیتهای پژوهش خود نیز اشاره میکنند. TAAROFBENCH هنوز ماهیتی ایستا دارد، درحالیکه فرهنگ پدیدهای پویا و در حال تحول است. از طرف دیگر، این مطالعه بر تعاملات تکنوبتی و صرفاً متنی تمرکز دارد، درحالیکه تعارف در گفتوگوهای واقعی در بستری چندمرحلهای، زبانی، و حتی غیرکلامی صورت میگیرد.
پژوهش همچنین به ملاحظات جدی اخلاقی نیز اشاره میکند. آموزش فرهنگیِ هوش مصنوعی اگر بهدرستی انجام نشود، ممکن است به بازنمایی نادرست فرهنگها یا حتی تقویت کلیشههای زیانبار بینجامد.
علاوهبراین، نگرانیهایی دربارهی حریم خصوصی کاربران، استقرار مسئولانهی مدلها، و خطر استفادهی دوگانه از تکنیکهای انطباق فرهنگی وجود دارد؛ جایی که ابزارهای طراحیشده برای همدلی و درک متقابل، میتوانند در دست نهادهای دیگر به ابزاری برای فریب یا دستکاری تبدیل شوند.
منبع: زومیت